









2025新澳精準資料大全,2025新澳門精準免費大全,新澳全年免費資料大全,2025年天天彩免費資料,2025澳門精準正版免費大全,2025新奧正版資料免費,2025新澳精準資料免費,2025新澳精準正版資料,2025新澳正版資料最新更新,新奧天天精準資料大全,2025新澳資料大全免費,2025正版資料免費公開,新澳2025正版免費資料,2025新澳精準資料免費提供下載,新奧長期免費資料大全,新澳新澳門正版資料,2025新澳正版免費資料大全,新奧精準免費資料提供,新澳精選資料免費提供新澳精準資料免費提供網,新澳精準資料免費提供網,新澳正版資料免費提供,2025澳門天天開好彩大全46期,新奧最快最準免費資料,新澳正版資料免費大全,2025新奧精準正版資料,2025年新奧正版資料免費大全,新澳準資料免費提供,新澳資料免費精準期期準,2025新澳資料免費大全,2025全年資料免費大全,2025新澳最快最新資料,2025新澳正版免費資料,新澳今天最新免費資料,新澳今天最新資料2025,2025新奧精準資料免費大全
193期:澳門天天好彩正版掛牌更多

|
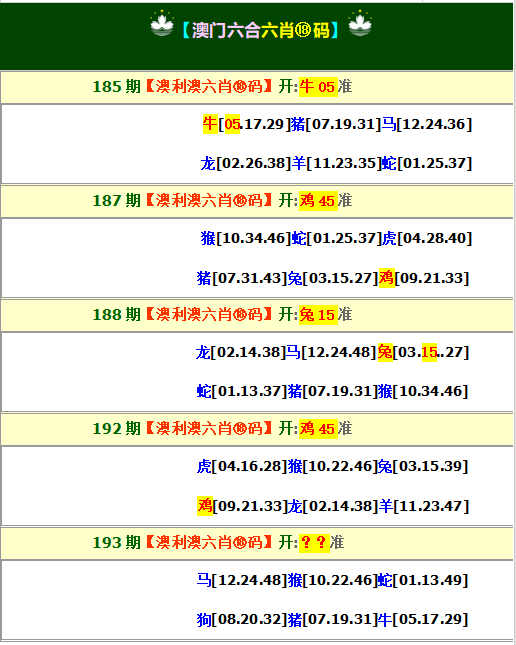
193期 | |
|---|---|---|
| 掛牌 | 17 | |
| 火燒 | 羊 | |
| 橫批 | 心蕩神搖 | |
| 門數 | 04,03 | |
| 六肖 | 牛兔虎蛇猴龍 | |
澳門精華區
香港精華區
- 193期:【貼身侍從】必中雙波 已公開
- 193期:【過路友人】一碼中特 已公開
- 193期:【熬出頭兒】絕殺兩肖 已公開
- 193期:【匆匆一見】穩殺5碼 已公開
- 193期:【風塵滿身】絕殺①尾 已公開
- 193期:【秋冬冗長】禁二合數 已公開
- 193期:【三分酒意】絕殺一頭 已公開
- 193期:【最愛自己】必出24碼 已公開
- 193期:【貓三狗四】絕殺一段 已公開
- 193期:【白衫學長】絕殺一肖 已公開
- 193期:【滿目河山】雙波中 已公開
- 193期:【寥若星辰】特碼3行 已公開
- 193期:【凡間來客】七尾中特 已公開
- 193期:【川島出逃】雙波中特 已公開
- 193期:【一吻成癮】實力五肖 已公開
- 193期:【初心依舊】絕殺四肖 已公開
- 193期:【真知灼見】7肖中特 已公開
- 193期:【四虎歸山】特碼單雙 已公開
- 193期:【夜晚歸客】八肖選 已公開
- 193期:【夏日奇遇】穩殺二尾 已公開
- 193期:【感慨人生】平特一肖 已公開
- 193期:【回憶往事】男女中特 已公開
- 193期:【瘋狂一夜】單雙中特 已公開
- 193期:【道士出山】絕殺二肖 已公開
- 193期:【相逢一笑】六肖中特 已公開
- 193期:【兩只老虎】絕殺半波 已公開
- 193期:【無地自容】絕殺三肖 已公開
- 193期:【涼亭相遇】六肖中 已公開
- 193期:【我本閑涼】穩殺12碼 已公開
- 193期:【興趣部落】必中波色 已公開
【管家婆一句話】

【六肖十八碼】
【六肖中特】
【平尾心水秘籍】
澳門正版資料澳門正版圖庫
- 澳門四不像
- 澳門傳真圖
- 澳門跑馬圖
- 新掛牌彩圖
- 另版跑狗圖
- 老版跑狗圖
- 澳門玄機圖
- 玄機妙語圖
- 六麒麟透碼
- 平特一肖圖
- 一字解特碼
- 新特碼詩句
- 四不像玄機
- 小黃人幽默
- 新生活幽默
- 30碼中特圖
- 澳門抓碼王
- 澳門天線寶
- 澳門一樣發
- 曾道人暗語
- 魚躍龍門報
- 無敵豬哥報
- 特碼快遞報
- 一句真言圖
- 新圖庫禁肖
- 三怪禁肖圖
- 正版通天報
- 三八婆密報
- 博彩平特報
- 七肖中特報
- 神童透碼報
- 內幕特肖B
- 內幕特肖A
- 內部傳真報
- 澳門牛頭報
- 千手觀音圖
- 夢兒數碼報
- 六合家寶B
- 合家中寶A
- 六合簡報圖
- 六合英雄報
- 澳話中有意
- 彩霸王六肖
- 馬會火燒圖
- 狼女俠客圖
- 鳳姐30碼圖
- 勁爆龍虎榜
- 管家婆密傳
- 澳門大陸仔
- 傳真八點料
- 波肖尾門報
- 紅姐內幕圖
- 白小姐會員
- 白小姐密報
- 澳門大陸報
- 波肖一波中
- 莊家吃碼圖
- 發財波局報
- 36碼中特圖
- 澳門男人味
- 澳門蛇蛋圖
- 白小姐救世
- 周公玄機報
- 值日生肖圖
- 鳳凰卜封圖
- 騰算策略報
- 看圖抓碼圖
- 神奇八卦圖
- 新趣味幽默
- 澳門老人報
- 澳門女財神
- 澳門青龍報
- 財神玄機報
- 內幕傳真圖
- 每日閑情圖
- 澳門女人味
- 澳門簽牌圖
- 澳六合頭條
- 澳門碼頭詩
- 澳門兩肖特
- 澳門猛虎報
- 金錢豹功夫
- 看圖解特碼
- 今日閑情1
- 開心果先鋒
- 今日閑情2
- 濟公有真言
- 四組三連肖
- 金多寶傳真
- 皇道吉日圖
- 澳幽默猜測
- 澳門紅虎圖
- 澳門七星圖
- 功夫早茶圖
- 鬼谷子爆肖
- 觀音彩碼報
- 澳門不夜城
- 掛牌平特報
- 新管家婆圖
- 鳳凰天機圖
- 賭王心水圖
- 佛祖禁肖圖
- 財神報料圖
- 二尾四碼圖
- 東成西就圖
- 12碼中特圖
- 單雙中特圖
- 八仙指路圖
- 八仙過海圖
- 正版射牌圖
- 澳門孩童報
- 通天報解碼
- 澳門熊出沒
- 鐵板神算圖
澳門正版資料人氣超高好料
澳門正版資料免費資料大全
- 殺料專區
- 獨家資料
- 獨家九肖
- 高手九肖
- 澳門六肖
- 澳門三肖
- 云楚官人
- 富奇秦準
- 竹影梅花
- 西門慶料
- 皇帝猛料
- 旺角傳真
- 福星金牌
- 官方獨家
- 貴賓準料
- 旺角好料
- 發財精料
- 創富好料
- 水果高手
- 澳門中彩
- 澳門來料
- 王中王料
- 六合財神
- 六合皇料
- 葡京賭俠
- 大刀皇料
- 四柱預測
- 東方心經
- 特碼玄機
- 小龍人料
- 水果奶奶
- 澳門高手
- 心水資料
- 寶寶高手
- 18點來料
- 澳門好彩
- 劉伯溫料
- 官方供料
- 天下精英
- 金明世家
- 澳門官方
- 彩券公司
- 鳳凰馬經
- 各壇精料
- 特區天順
- 博發世家
- 高手殺料
- 藍月亮料
- 十虎權威
- 彩壇至尊
- 傳真內幕
- 任我發料
- 澳門賭圣
- 鎮壇之寶
- 精料賭圣
- 彩票心水
- 曾氏集團
- 白姐信息
- 曾女士料
- 滿堂紅網
- 彩票贏家
- 澳門原創
- 黃大仙料
- 原創猛料
- 各壇高手
- 高手猛料
- 外站精料
- 平肖平碼
- 澳門彩票
- 馬會絕殺
- 金多寶網
- 鬼谷子網
- 管家婆網
- 曾道原創
- 白姐最準
- 賽馬會料
東莞市麗飛包裝制品有限公司(dglfbz.com)成立于2023年09月19日,注冊地位于廣東省東莞市東城街道溫塘塘邊頭街14號308室,法定代表人為吳曉清。經營范圍包括一般項目:包裝材料及制品銷售;機械設備銷售;塑料制品銷售;新澳天天開獎資料大全最新版,7777788888管家婆鳳凰網,2025新澳天天免費大全,2025全年免費資料大全,新澳門2025最精準免費大全,新澳天天開好彩資料大全,2025新澳門精準正版免費紙制品銷售;合成材料銷售;生態環境材料銷售;新材料技術研發;化工產品生產。(ICP備案號)
友情鏈接:百度
網站的廣告和外鏈,所有內容均轉載自互聯網,內容與本站無關!
本站內容謹供娛樂參考,不可用于不法活動,嚴禁轉載和盜鏈等!并且防止相關欺騙性內容。
Copyright ?2012 - 2024 新澳天天開獎資料大全最新版,7777788888管家婆鳳凰網,2025新澳天天免費大全,2025全年免費資料大全,新澳門2025最精準免費大全,新澳天天開好彩資料大全,2025新澳門精準正版免費 All Rights Reserved
